 |
| Artwork by Cheeky4n6Monkey |
A while ago I wrote a blog post about the Google Analytic Cookies and the Cache files. Rather then focus on how to parse these artifacts like previous posts, this post will dive into how you can use deleted Google Analytic artifacts to build a much more comprehensive timeline as well as how to recover them using Scalpel.
(Or you can watch me talk about it on the Forensic Lunch if you prefer, but I have more detailed instructions here)
Building out the Timeline
I had a case where the user account was deleted, and the client wanted Internet History recovered to show a pattern of activity - not just that the user had been to a site once, but many times over the course of the time they had access to the computer.
Although I tried two commercial tools to recover deleted Internet History, it was very little and over a short period of time. This is where Google Analytic artifacts stepped in and saved the day. I was able to recover a large amount of cookies from unallocated space and cache files to build up a timeline that showed a pattern over time - much, much more then the Internet History I recovered with the commercial tools. Even if you are working with an existing user account, adding these artifacts can build out your timeline even more. I'll explain what I mean below.
Normally, when a cookie is viewed through a tool such as NetAnalysis, you are presented with a Last Visited Date, Hit Count and Domain name:

Take the cookie highlighted above in blue for an example. By looking at the displayed information we know the host name, last time the domain was visited and how many hits it had. But what do the hits mean exactly? Were all of these 136 hits done in one day? Were they spread out over the course of the year? What about all the days/visits prior, if any?
This is where the power of recovering deleted Google Analytic artifacts can help build out a timeline. Take for example the _utma cookie. This cookie has three timestamps as opposed to the one timestamp of a "regular" cookie. After recovering some of these __utma cookies with the same host name, we can start to build up a timeline that has way more information. (The following spreadsheets were generated by using GA Cookie Cruncher to parse the recovered cookies)
Recovered __utma Cookies

The __utmb cookie stores session information for each visit to a website. It expires after 30 minutes of inactivity. This __utmb cookie not only stores the time of the session, but how many pages were viewed during that session. This means that if a user visits a website twice in one day, say before and after work, two separate__utmb cookies would have been created. Once in the morning with a page count for that visit, and once in the evening with a new page count for that visit. Since the only the last cookie is saved, we would only have one count for the page views. If we recover the cookies that existed previously, we can see a session count for those previous visits and add those to the timeline:
Recovered __utmb Cookies

Recovered __utmz Cookies

Now if we combine all cookies into one sheet for review:
All Recovered __utm Values

Look at all the information that is now available compared to viewing just the one existing cookie! Instead of being presented with one visit date and one hit count, we now have previous visits, keywords, referral pages and how many pages were viewed in each session. This can further be built upon by adding the __utm?gif cache values which can have over 30 other variables such as page title and referral page. I have also seen values like usernames in the cached URLs which could extremely helpful.
Recovering Deleted Cookies
The real power of the Google Analytic artifacts comes into play when deleted artifacts are recovered. By using Scalpel and then parsing the carved files you can have some new data to play with and analyze.
Based on some initial and limited testing with Internet Explorer 11 and Windows 7, it appears the browser deletes then creates a new cookie when visiting a website rather then overwriting the old cookie. This means there could be a lot of cookies waiting to be recovered.
Scalpel is a great program for recovering, or 'carving' for deleted files. It's a command line tool which is included in the Sift Workstation, or it can be downloaded from here.
By default, Scalpel does not carve for Google Analytic Cookies and cache files, but that is easily fixed by adding in a few lines to the Scalpel configuration file (mine was located under /user/local/etc/scalpel.config):
 |
| scalpel.config |
I added five entries into the configuration file in order to locate Internet Explorer and Safari Binary Cookies and Cache files. (I'm still working on the best way to carve out then parse cookies that are stored in SQLite databases, such as Firefox and Chrome.)
If your unfamiliar with how to use Scalpel or need a refresher,Cheeky4n6Monkey has a great post on how to use Scalpel, including how to add custom carvers like these.
The configuration file itself has detailed instructions on how to add custom file types, but here is a quick explanation of the entries I've made. The first column is the file extension. In this case it's arbitrary and you can use whatever you like here. For instance, I could have also used .txt instead of iec (which I chose to stand for Internet Explorer Cookie).
The second column is whether or not the header is case sensitive. In my test data for IE, I have always seen them in lowercase so I used 'yes' to help reduce false positives.
The third column is the max size for the file we are carving. Since each IE cookie should be relatively small, I have used 1000 bytes as the value.
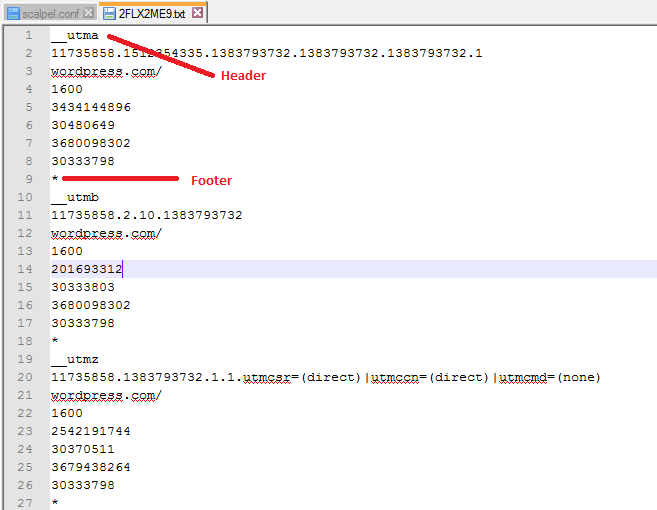
For the header and footer, if we view the Internet Explorer Cookies in a text editor, we can see that each cookies starts with a __utm value and ends with a '*' - these will be the header and footer respectively for each carved cookie:
The cache file store the __utm.gif? values in plain text. The goal is not to recover the entire cache file, but just the __utm_gif? URL and values. Below is a picture of a Firefox cache file:

By using the string "google-analytics.com/__utm.gif?" as a header, and specifying 1000 bytes, it should extract the whole URL plus a little extra for padding to be safe. (To read more about the __utm.gif values in cache files, check out my blog post here.)
When Scalpel carves all these file types, they will each be dropped into their own sub directory automatically.
To run scalpel:
scalpel -c /usr/local/etc/scalpel.conf -o carvedcookies /cases/myimage.dd
Opening up each carved file and manually parsing it for all the _utm values could be pain, especially if you have hundreds of recovered files. To that end, I have updated GA Cookie Cruncher to handle carved cookies for Internet Explorer and Safari Binary Cookie Parser for Safari Binary Cookies.
What do I mean by "handle"? When recovering files, sometimes the files are fragmented, incomplete or there may be some false positives. For example, if you were to try and open an incomplete Word Document in Word, it might close and give you an error. Both of the above programs can handle these situations. If the file is incomplete, it tries to get as much information as it can, then moves on to the next file.
(To that end, it worked on my test data. If it crashes on yours, shoot me an email and I'll see what I can do)
What this means is that once you carve the files, you just need to point the programs at the directories and let them parse as many values as they can.
So in summary, the following steps can be followed to recover and parse deleted Google Analytic values for Internet Explorer and Safari:
- Update the Scalpel config file with the carvers
- Run Scalpel over the image
- For Internet Explorer, point GA Cookie Cruncher to the directory holding the IE recovered cookies
- For Safari, run the Safari Binary Cookie parser with the directory option (-d) to the directory holding the recovered binary cookies.
- For Cache records,point the Gis4Cookie parser with the directory option to the directory holding the recovered cache files
- Analyze the generated spreadsheets and build out your timeline.
There might be a few more steps involved then just pushing a button, but in my case is was worth it.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}