Another way an attacker can access a system remotely is to use a program called WinSCP. Using
WinSCP, they can browse folders and files on a remote system, copy folder and files back to the system they are currently on, and even search the remote system for files!

The scenario I am going to focus on here is one where the attacker has already compromised a system on the network, and is using WinSCP to browse to other computers on the same network. In this case, they could browse to HR systems looking for tax information, Severs looking for databases or Workstations looking for IP data. (Note - TLDR at the bottom)

Because they are not using the Windows Explorer shell, this leaves very little artifacts on what they were doing on the remote system in comparison to RDP. Basically, they get a browse for free card. They can even open up remote documents from within a WinSCP text editor.
An argument may be made that RDP is available by default on Windows systems while FTP/SSH is not. Well, guess what. Starting with Windows 10 1809 and Sever 2019 it is part of the "optional features " that can be easily installed on Windows. In fact, a simple PowerShell command can be used to install it. And, on top of that, it automatically creates a firewall rule and adds an SSH user. How thoughtful!
powershell Add-WindowsCapability -Online -Name OpenSSH.Server~~~~0.0.1.0
powershell Start-Service sshd
powershell Start-Service sshd
And as a bonus, add the command to have the service start up automatically:
powershell Set-Service -Name sshd -StartupType 'Automatic'
It is not uncommon for an attacker to follow the below steps once they have breached a network:
1) Dump admin credentials
2) Enumerate systems to get IP addresses/Hostnames
3) Push out PowerShell scripts to all systems en-mass that do things like disable firewalls, install backdoors and disable antivirus.
It's a simple task to add in one more command to install SSH and now boom - all these systems are now accessible to connect to using WinSCP.
Oh - and did I mention that WinSCP comes with a portable version? The portable version makes it easy for an attacker to download and use. Many blog posts reference a registry key that contains settings for WinSCP. However, the portable version does not store settings there.
So - now that we know WinSCP can be used in this manner, what artifacts can we find forensically to help determine what was done on both the "staging" system and the remote systems? I did some testing on some Windows 10 1909 machines to see what artifacts were left behind using the Portable version of WinSCP, v.5.17.
WinSCP Client System Artifacts
Most of the artifacts related to WinSCP are going to be on the host where it was run. Running WinSCP generates many of the common artifacts seen with file execution: Prefetch, shimcache, amcache, userassist etc. However, the artifacts "for the win" will be the WinSCP.ini file and the SRUM database.
WinSCP.ini file
WinSCP.ini is a text file that contains configuration settings. It will be located in the same directory as the WinSCP.exe file. At the end of a WinSCP session, the user is promted to save their workspace:

Even without saving the wokspace, WinSCP saves valuable information in the WinSCP.ini file that can be useful to the investigation. This includes systems connected to,usernames, places on the local system where files were saved to from the remote system and the last path that was accessed on the local system. Examples of each of these configuration sections are below:
Systems connected to:
[Configuration\CDCache]
ItSupport@169.254.249.229=412F433A2F55736572732F<SNIP>
mdegrazia@169.254.171.129=412F433A2F55736572732F<SNIP>
ITSupport@DESKTOP-PV2TN0G=412F433A2F55736572733D<SNIP>
Folders where files have been saved:
[Configuration\History\LocalTarget]
0=C:%5CUsers%5CCrashOveride%5CDocuments%5CExfil%5C*.*
1=C:%5CUsers%5CCrashOveride%5CDocuments%5CSystem3%5C*.*
Last folder opened on the local system:
[Configuration\Interface\Commander\LocalPanel]
DirViewParams=0;1|150,1;70,1;120,1;150,1;55,0;55,0;@96|5;4;0;1;2;3
StatusBar=1
DriveView=0
DriveViewHeight=100
DriveViewHeightPixelsPerInch=96
DriveViewWidth=100
DriveViewWidthPixelsPerInch=96
LastPath=C:%5CUsers%5CCrashOveride%5CDocuments%5CExfil
If the session settings are saved, you get a bonus section called Sessions, with the saved session name. The default is "My Workspace" . This saves the last local directory and remote directory, along with a password. Check out https://github.com/winscp/winscp/blob/master/source/core/Security.cpp for information on the password encryption.
[Sessions\My%20Workspace/0000]
HostName=169.254.44.249
UserName=ITSupport
LocalDirectory=C:%5CUsers%5Cmdegrazia%5CDocuments%5CSystem3%5CW2s
RemoteDirectory=/C:/Users/Acid%20Burn/Documents/W2s
IsWorkspace=1
Password=A35C435B9556B1237C2DFE15080F2<TRUNCATED>
The WinSCP.ini file appears to be updated when the session closes. As such, using the last modified date of the WinSCP.ini file with a prefetch timestamp could give you an idea of how long the last session was.
As you can see by the information above, looking at this .ini file can help an examiner determine what an attacker may have been browsing to on a remote system, and what they may have saved on the local system, even if it was subsequently deleted.
SRUM Database
The SRUM database collects information every hour on network usage on a per application basis. To get an idea of how much data may have been copied/downloaded using WinSCP it can be an excellent resource. Parsing the SRUM database with SRUM Dump by Mark Bagget shows that a high amount of data was transferred using WinSCP:

As demonstrated above, if you suspect WinSCP was used, parsing out the database can provide some details on how much data was transferred, what user account was associated with it, and the time frames that it occurred. Beautiful!
WinSCP Remote System Artifacts
There are several things you can look for on a remote system to determine if WinSCP was used to browse it: Event log entries, evidence of OpenSSH being installed and file system timestamps. Note - in my example and for my testing I installed OpenSSH which is part of Windows. WinSCP can use other FTP/SSH servers to connect to. Keep that in mind if you suspect WinSCP may have been used - your artifacts may vary.OpenSSH artifacts
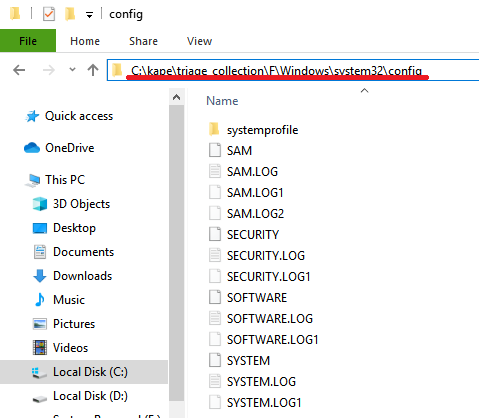
As mentioned previously, in order for WinSCP to connect to a system, an FTP or SSH sever must be running to accept the connection. Look for artifacts indicating these services exist. For OpenSSH, look for c:/Windows/System32/OpenSSH/sshd.exe, SSHD.exe prefetch files, and the sshd.exe service. Timestamps associated with these entries may help determine the first time the attacker used it to connect. When I installed OpenSSH, it also created a user account, which can be located in the SAM hive (shown here parsed with RegRipper):Username : sshd [1003]
SID : S-1-5-21-1445295406-4253784506-242647837-1003
Full Name : sshd
User Comment :
Account Type :
Account Created : Sun Feb 23 06:48:08 2020 Z
Name :
Last Login Date : Never
Pwd Reset Date : Sun Feb 23 06:48:08 2020 Z
Pwd Fail Date : Never
Login Count : 0
--> Password does not expire
--> Normal user account
Event Log Entries
As expected there is an Event ID 4624 associated with the WinSCP client login. The login is a type 5 with the account name sshd_1860 and the domain of VIRTUAL USERS, and the process of sshd.exe:

File Timestamps
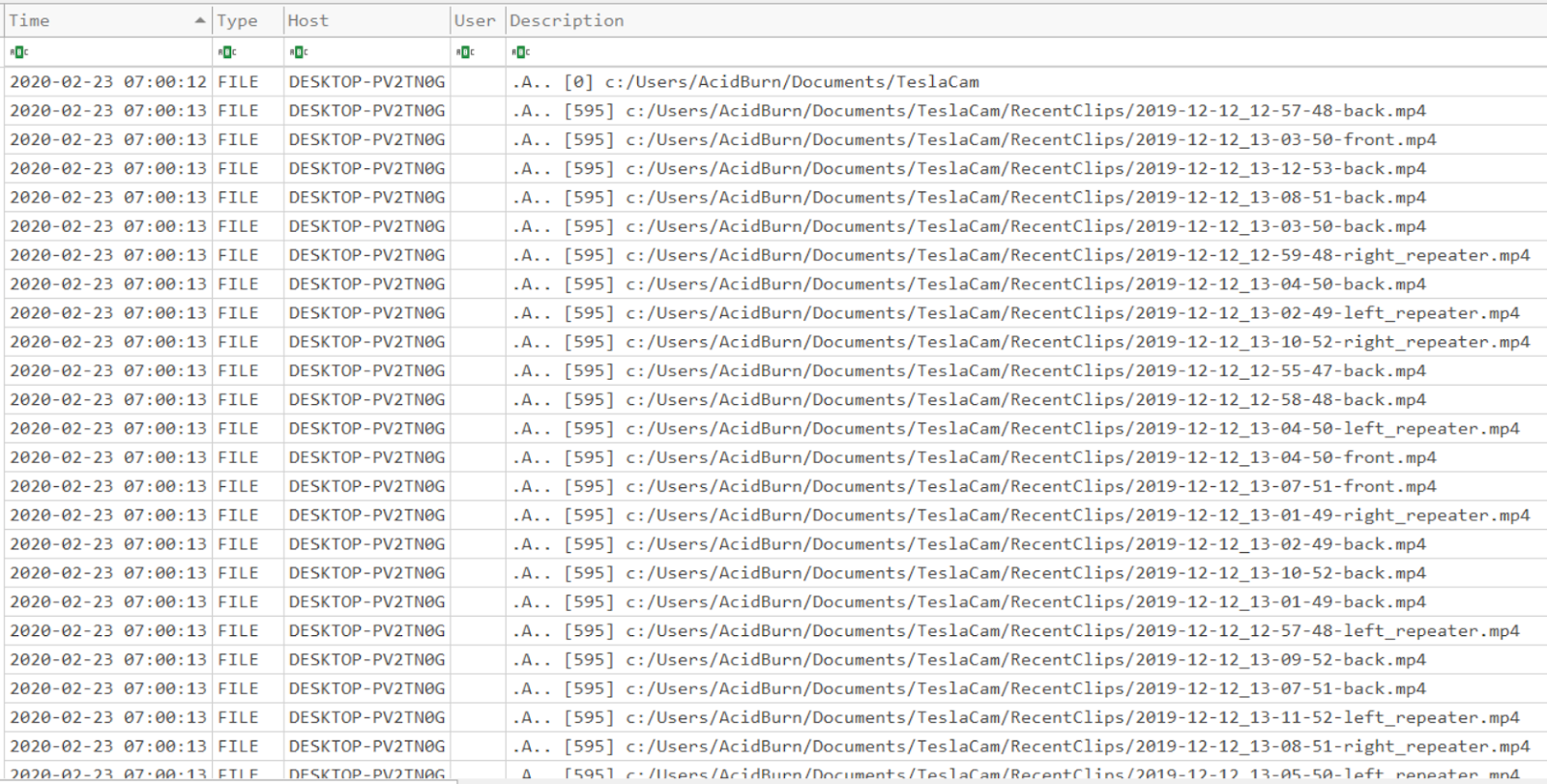
Once logged in, the attacker can use WinSCP to effectively browse through folders, and even open up files via WinSCP leaving very little trace on the remote system. During testing, I noticed that an indication this was occurring was that accessed dates were changed on folders and files clicked on or copied. However, access dates are NOT a reliable artifact to use when drawing conclusions and must be used with other corroborating artifacts.
Below is an example of files and folders that were copied. The "Teslacam" folder was copied, which results in the access dates of all the copied files to be updated on the remote system:
SRUM Database
Once again, the SRUM database really shines here to know if something is amiss. Looking at the SRUM database and sorting by "Bytes Sent" shows a large amount of data being sent during this time frame by the application sshd:

<TLDR>
So, in summary. WinSCP can be used by attackers as an alternative to RDP. The use of WinSCP to access systems in an environment appear to leave a smaller footprint than using RDP. Now that SSH can be easily installed into Windows 10 and Windows Server 2019, I anticipate we may see WinSCP being used more in network breach cases to move around laterally within the environment.
Look for the WinSCP.ini file on the host system and the SRUM datbase. For the remote system, look for Event IDs 4624 related to ssh clients/servers and Application logs for FTP/SSH severs. Check the SRUM database for data transfers related to ssh clients. Once a timeframe is known, check for large amounts of files that have last access timestamps in the same timeframe (but you know the drill with last access dates - be very careful using these)
Sources/References:
WinSCP: https://winscp.net/eng/index.php
Installing OpenSSH on Windows: https://docs.microsoft.com/en-us/windows-server/administration/openssh/openssh_install_firstuse
SRUM dump : https://github.com/MarkBaggett/srum-dump