 |
What tipped me off that the profile was not being parsed correctly? Several things. One program I used parsed only 274 messages. Based upon the large size of the profile, this seemed suspect to me. I tried another program and it parsed over 5,000 emails from the same profile. Quite a discrepancy. When I tried to view the profile natively using Thunderbird, it threw errors.
This caused me to take a closer look at the Thunderbird files, and untimely, write a python parser to extract the emails – including deleted ones.
Testing
Because the email profile was corrupted, I wanted to test the same programs with a "normal" profile. I actually use Thunderbird as my email client, so I had a decent profile for testing with over 7,000 emails in my Inbox and about 3,300 in my sent folder over the course of a couple of years.
I parsed my profile with three forensic programs as well as just viewing it in Thunderbird. I also ran the python script I wrote over it (noted as TB Parser below). I was surprised by the variety of results - many programs were not getting all the messages. I've listed the major email folders from the Thunderbird profile below and the number of parsed emails from each program:

A possible reason for these discrepancy is the format in which Thunderbird stores its emails. Thunderbird uses a modified version of the MBOX email format, called MBOXRD1.This may account for the partial processing of emails as many of the tools support state support for MBOX. However, Tool 1 states in it's documentation specific support for Thunderbird.
So if the tools states support for Thunderbird, or if you see some emails but they are all not being parsed, is the tool to blame? I think it may be a little misleading that some of the emails are parsed, however, I believe that it is incumbent upon the examiner to verify the results and understand the way that the tools work. However, that being said, sometimes it's easier said then done. I had a situation where it was pretty obvious all the emails had not been parsed. What if the profile size was 1GB and 5,000 emails were parsed? Is that a reasonable number? What if it was supposed to be 6,000 and your smoking gun is one on the ones that didn't get parsed?
Thunderbird Configuration
First, a little background information on Thunderbird. Thunderbird allows a user to set up both POP and IMAP email. Once a user has set up and configured their profile, it’s stored under the following location (at least on Windows 7):
C:\Users\%USERNAME%\AppData\Roaming\Thunderbird\Profiles\[Random].default
Unlike Outlook, the data is not stored in one file, but rather a series of files and folders under the profile directory. If you want to view this profile natively with Thunderbird, the easiest way I have found so far it to launch Thunderbird from the command prompt with the –profile switch and point it to the path where you have exported out the profile. Make sure you’re not connected to the Internet if your doing this on an evidence profile. The last thing you want to do is download new email or send out a message that has been sitting in the outbox. This may (and probably will) modify the file, so only do it on a copy.

Once launched, a typical setup may look like this:

Of course, being forensicators, this may not be the preferred way to review emails - but sometimes it's nice or even necessary to see files in the native viewer/program.
A whole bunch of files are created under the root of the profile directory. These include files like cookies.sqlite, places.sqite and formhistory.sqlite that may warrant a peek. However, I am going to focus on the email files for now.
Email Files
Thunderbird stores the IMAP mail profile in a sub folder named "ImapMail" while POP mail and Local Folders are stored in a sub folder named "Mail":

There are several files that hold information related to emails. The first is the global-messages-db.sqlite file. This file is located in the root of the profile folder:

Global-messages.db.sqlite Database
The global-messages.db.sqlite is an SQLite database that Thunderbird uses to index and search messages.2 This file can be viewed using an SQLite Browser. The "mesagesText_Contents" table contains the Email Body, Subject, Author, Recipients and Attachment Names.
The global-messages.db.sqlite is an SQLite database that Thunderbird uses to index and search messages.2 This file can be viewed using an SQLite Browser. The "mesagesText_Contents" table contains the Email Body, Subject, Author, Recipients and Attachment Names.
| messagesText_Contents Table |
 |
While this database contains email information, the email body is not a
true representation of the email. For example, the body field does not
contain images or attachments. Also, it does not contain messages that
have been deleted, whereas the MBOXRD file can (discussed below).
However, it does contain some useful data, such as the name of the
attachments of non-deleted emails. You could browse this database quickly to see if any
attachment names are suspicious.
Using "docid" in the messagesText_Contents table, you can link it back to the “messages”table id field. The messages table contains information about each message, such as the headerMessageID and jsonAttributes. The jsonAttirbutes are what stores whether a message has been read, forwarded or replied to among other things.

The headerMessageID is also located in the MBOXRD file - which is what I used to link the raw MBOXRD data back to global-messages.db.sqlite database. You may noticed there is a deleted column here. Based upon limited testing, I believe that this value is used during the synching of the IMAP mail. When a message is deleted, it remains in this database with a 1 until the corresponding message is deleted on the mail sever. Once it has been deleted, the message is removed from the database, but remains in the MBOXRD file. Normally all these values will be '0' unless the user was offline when the message was deleted.
In my particular case, this sqlite file was corrupt and I did not have access to these tables. This may also be why one of the programs did not parse the email fully - maybe it was relying on the table, who knows. I have written my parser so that it does not need this database to process the emails. It merely displays "Data not available" for the fields that it can't pull from the table.
Using "docid" in the messagesText_Contents table, you can link it back to the “messages”table id field. The messages table contains information about each message, such as the headerMessageID and jsonAttributes. The jsonAttirbutes are what stores whether a message has been read, forwarded or replied to among other things.
The headerMessageID is also located in the MBOXRD file - which is what I used to link the raw MBOXRD data back to global-messages.db.sqlite database. You may noticed there is a deleted column here. Based upon limited testing, I believe that this value is used during the synching of the IMAP mail. When a message is deleted, it remains in this database with a 1 until the corresponding message is deleted on the mail sever. Once it has been deleted, the message is removed from the database, but remains in the MBOXRD file. Normally all these values will be '0' unless the user was offline when the message was deleted.
In my particular case, this sqlite file was corrupt and I did not have access to these tables. This may also be why one of the programs did not parse the email fully - maybe it was relying on the table, who knows. I have written my parser so that it does not need this database to process the emails. It merely displays "Data not available" for the fields that it can't pull from the table.
Just a heads up, there is more data that could be mined from this database, such as IM Conversations but I am trying to stay focused on email.. so moving on.... (and who uses Thunderbird to IM anyways????)
MBOXRD aka The Payload
Thunderbird stores email in an mbox format called MBOXRD. Basically, it stores email in plain text MIME format. The cool thing is (based upon my testing and some internet research) when an email is deleted, it stays in this file. These deleted emails would not be seen if this profile was viewed using the Thunderbird client. The thunderbird parser pulls all the emails from these files, including deleted ones.
The MBOXRD files are stored in file that is named after the corresponding email folder with no file extension. For example, the Inbox folder stores its emails in the "INBOX" file":

One level deeper, in the .sdb folder are the other folders such as the Sent folder and any user created folders to store email:

.MSF files
For each MBOXRD file, there is a corresponding .msf file. The .msf file contains folder indexes and preference data in Mork format. According to internet research, this file format has taken a lot of heat as being a pain to work with. The pointers for messages marked as Junk by Thunderbird appear to be tracked in here (based upon my limited testing). However, the formatting of the Message-ID's in this file are whacked. They include backslashes and if they are to long, they can also include the newline "\n" character as well.
Deleted Files
As mentioned before, when a file is deleted it is removed from the database yet still remains in the MBOXRD file. In order to determine if a file is deleted, the headerMessageID in the MBOXRD file can be cross referenced back to the database. However, emails that have been marked as "Junk" mail by Thunderbird are not stored in the global-messages.db.sqlite either. The "Junk" emails appear to be stored in the corresponding MBOXRD .msf file. So two checks need to be done to determine if a file has been deleted. The logic is as follows:

For each MBOXRD file, there is a corresponding .msf file. The .msf file contains folder indexes and preference data in Mork format. According to internet research, this file format has taken a lot of heat as being a pain to work with. The pointers for messages marked as Junk by Thunderbird appear to be tracked in here (based upon my limited testing). However, the formatting of the Message-ID's in this file are whacked. They include backslashes and if they are to long, they can also include the newline "\n" character as well.
Deleted Files
As mentioned before, when a file is deleted it is removed from the database yet still remains in the MBOXRD file. In order to determine if a file is deleted, the headerMessageID in the MBOXRD file can be cross referenced back to the database. However, emails that have been marked as "Junk" mail by Thunderbird are not stored in the global-messages.db.sqlite either. The "Junk" emails appear to be stored in the corresponding MBOXRD .msf file. So two checks need to be done to determine if a file has been deleted. The logic is as follows:
{kind=link}
Thunderbird Email Parser
The python thunderbird email parser does three things:
1) Provides an Excel Sheet with the following information: file the email came from, address information (from, to, cc, bc), subject, raw date, converted date (in UTC) a link to the exported email and a list of attachments:

2) If the corresponding global-messages.db.sqlite is readable, it will provide TRUE/FALSE values for read, replied forwarded and if the message was deleted. If a message was deleted, the database format has changed, or the database is corrupt, these fields will say "Data not available".
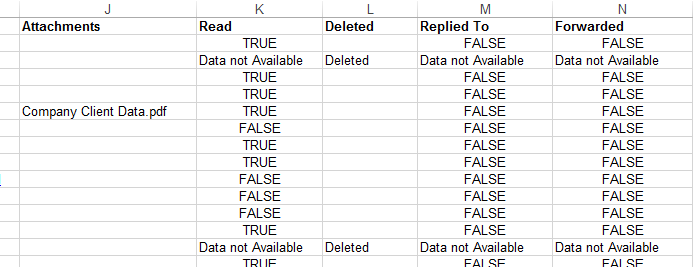
3) It exports all the emails into a subfolder named "emails". Each email is named with the timestamp, email subject and unique number.

1) Provides an Excel Sheet with the following information: file the email came from, address information (from, to, cc, bc), subject, raw date, converted date (in UTC) a link to the exported email and a list of attachments:
2) If the corresponding global-messages.db.sqlite is readable, it will provide TRUE/FALSE values for read, replied forwarded and if the message was deleted. If a message was deleted, the database format has changed, or the database is corrupt, these fields will say "Data not available".
3) It exports all the emails into a subfolder named "emails". Each email is named with the timestamp, email subject and unique number.
Normally, when I write a parser, I like to dump the output into a CSV, TSV or a plain text file. This proved difficult for two main reasons.
First, many of the email addresses and strings within the email body contained tabs and commas which threw the formatting off.
Second, I needed a way to supply the body of the email. Putting a large body of an email into one cell looked ugly. Also, html was not displayed as one would see it in an email client making it difficult to read.
For this reason, I decided to put the output into an Excel sheet. So in order to use the parser, the xlwt python libary needs to be installed which is pretty quick and easy to do for either the Windows or Linux platform. For Linux, you can use easy install. For Windows, you can downalod the installer for xlwt at https://pypi.python.org/pypi/xlwt/0.7.2
For this reason, I decided to put the output into an Excel sheet. So in order to use the parser, the xlwt python libary needs to be installed which is pretty quick and easy to do for either the Windows or Linux platform. For Linux, you can use easy install. For Windows, you can downalod the installer for xlwt at https://pypi.python.org/pypi/xlwt/0.7.2
To use the parser, simply point it at the profile directory and select a directory for the output. The script will recurse through all subdirectories, so if you export out the user profile, make sure it goes in it’s own directory:
A report.xls file will be created along with a log file in output folder. The .eml files will be placed in a subdirectory named “emails”.
Some things to note, you may notice duplicate emails. This is because some emails may be stored in several folders, thus the email is stored in multiple files. For example, an email may be in the Inbox, as well as the All Email folder. Why not remove duplicate emails? Well, there may be significance if you find an email has been stored in a particular folder.
I am using a built in MIME python library to parse the emails. If an email does not follow this standard, the output may not be as expected -weird characters, etc. This is why I put the file name in the Excel sheet. You can always refer back to the original MBOXRD file to verify the results.
Although I have made every effort to test this script, and to make sure it is working accurately, verify your own results - which you should be doing anyways, right? ;-)
For deleted emails, I have made the notation "Deleted (Verify)". I did this because there is not a specific flag or variable to designate that the email has been deleted. I run through several checks to located the Message-ID to determine if the file has been deleted. It seems to be working pretty good, but I have a limited set of test data. How can you verify if the message has been deleted? One way would be to open the profile in Thunderbird and use Thunderbird to search for the email. If the user deleted the email, it would not show up in Thunderbird.
I have tested this on Thunderbird 24.4.0 using Windows 7 and the SIFT workstation with Python 2.7. If you want a Python 3+ version, I like shiny things and K-cup hot chocolate.
Given the frequency Mozilla tends to update things, there is always a chance that a new version may break the code. If you run into a situation where it doesn't work on a new or older version of Thunderbird, shoot me an email and I'll see what I can do.
As always, feedback and suggestions are welcome (If you're nice about it. Otherwise it goes right in the spam folder).
Download Thunderbird email parser.
References:
1. Library of Congress "Sustainability of Digital Formats Planning for Library of Congress Collections, MOBXRD Email Format."
2. Mozilla Foundation. "Rebuilding the Global Database"
Hi, thank you for your work, script and a great blog. I will have a run with your script next time a case requires it. Can I ask is there any reason why you have not mentioned the other tools you have tested? Knowledge of tools not producing accurate results is important to analysts using them to know about the issues and to assist the software vendor to address them. Despite being able to have a good guess at what software you have used, I would consider it worth sharing this as well? Thank you again for your work.
ReplyDeleteForgery,
ReplyDeleteThat is an excellent point, and one that I debated. I feel if I am to mention the tools, I should have a well documented writeup of the tools and results. For this post, I wanted to focus on the fact that some tools might be missing something, and to provide another option. The time and research I put into the Thunderbird parser was substantial, and by the time I was ready to post, I didn't want to drag it further out with a documented write up of the other tools. Maybe I will do a separate post of the tools I used and the results to share with the community/vendors.
Thanks for the feedback!
Hi, great tool but a couple of bugs to report.
ReplyDeleteFirst, if corporate emails everyone you can end up with a to-list longer than the cell size limit, 32767 characters. This causes the tool to die in xlwt in UnicodeUtils.py upack2... trimming in tbParser would be friendly, but I ended up editing upack2 to trim anything that mattered.
Second, I'd suggest you don't use a formula to hyperlink the files. Excel can't automatically remove them if they're not an HLINK as far as I can tell, and some tools like xlrd can't recover the file names at all from the formulas. It would be better to create another column that just says 'File' in each cell and stick a link behind that.